Check out what's going on

Time Traveling in Data Lakes
- Data & Artificial Intelligence

Łukasz Okrąglewski

Through time data lakes evolved while big companies like Netflix or Apple pushed the envelope to its limits and needed to organize table formats better to get information faster. In this blog post, I will explain one of the newest features of modern data lakes – time travel.
What is Data Lake?
First, let’s start with the basics. If you haven’t heard about data lake before, the fastest definition is the following: it is a place that ingests data from multiple sources and makes this data easily accessible at scale to everybody who needs data.
At some level, it can look like this:

Evolving Data Lake
At the beginning of data lakes, only experienced engineers could access the data because files lived on HDFS, and to get access to them you had to write a custom map-reduce program in Java and run it to get answers to your questions. It wasn’t reliable so engineers at Facebook created Hive to take SQL queries and automatically translate them to map-reduce jobs to run against HDFS.
But Hive was much larger than an only project to translate SQL scripts it introduced Table formats. That increased the speed of queries by organizing data in tables. As time went by, new players emerged to address issues that Hive couldn’t resolve. These players, among others, were Apache Hudi, Apache Iceberg and Delta Lake. The general idea was to create an additional layer with extra capabilities for handling data at scale.
What is time traveling?
One of the most excellent tools that were brought by new table formats was time traveling. Pretty neat, don’t you think? Sadly, this time only your data will travel in time, so put your DeLorean back to the garage. The approach to using time-traveling differs from one format to another, but the rule stays the same. We have chosen a point in time from the past ,and get the state of the data from that time regardless of the current state of the data.
How does it work?
To achieve time traveling, first we have to store every state of a data in a given time. This is possible thanks to snapshots which are stored in the log. Different technologies may have a different name for it, but the mechanism is very similar. We use some parallel computing engine to look through logs and bring up the snapshots we want.
Now that we have a brief idea about time-traveling, let’s check how to use it in the three most popular data lake formats: Delta Lake, Iceberg and Hudi.
Delta lake is a transactional storage layer designed to work with Apache Spark and take advantage of the cloud.
The project started from collaboration with Apple. During one of SparkSummit, an engineer from the InfoSec team at Apple had a chat with Michael Armbrust. His task was to process data from a network monitor that ingested every TCP and DHCP connection at a company, which results in trillions of records a day.
He wanted to use spark for processing, but spark alone wasn’t enough to handle this volume of data. So that’s how delta lake was born.
Delta lake started as a scalable transaction log. Collection of the parquet files and records of metadata that gives scalability and atomicity. Delta transaction log is written in a way that can be processed by Spark. Scalable Transactions to the entire system to managing and improving the quality of data in a data lake.
Delta Lake offers time traveling as part of Databricks Delta lake, this feature versions data stored in a data lake and lets you access any historical version of data.
Simple example
Accessing historical data can be done in two different ways:
Version number
Apache Iceberg
Iceberg is different from Delta and Hudi because it is not bound to any execution engine and it is a universal table format. Therefore, it could be used by streaming service of choice. It has its origins at Netflix.
Here is a list of terms used in Iceberg to structure data in this format:
- Snapshot – state of a table at some time
Each snapshot lists all of the data files that make up the table’s contents at the time of the snapshot.
- A manifest list – metadata file that lists the manifests which make up a table snapshot
Each manifest file in the manifest list is stored with information about its contents, like partition value ranges to speed up metadata operations.
- A manifest file – metadata file that lists a subset of data files which make up a snapshot
Each data file in a manifest is stored with a partition tuple, column-level stats and summary information used to prune splits during scan planning.
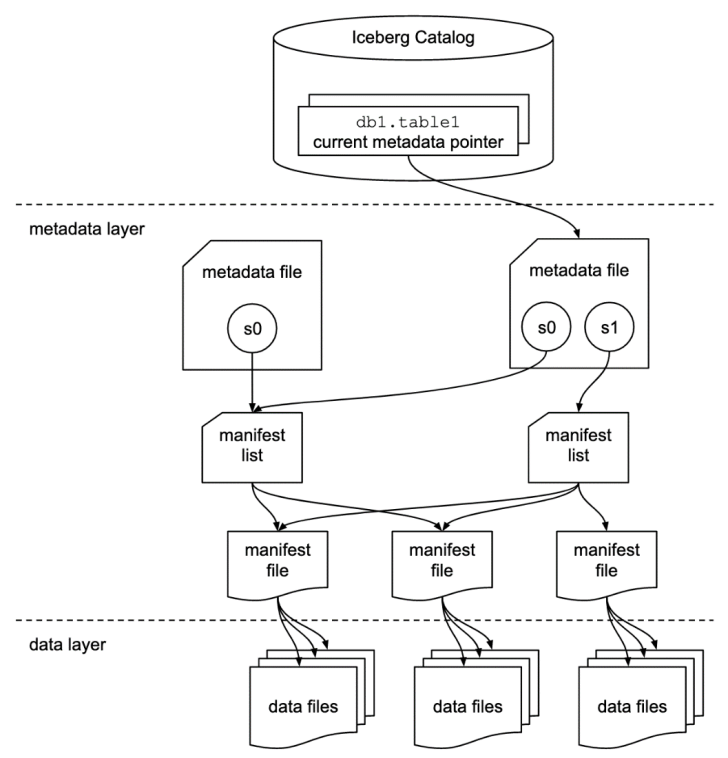
For a more detailed explanation about the architecture of Apache Iceberg, check out this blog post by Jason Hughes from the Dremio team:
https://www.dremio.com/apache-iceberg-an-architectural-look-under-the-covers/
For consistency in examples, we are still using Apache Spark as an engine. You can have two options to perform time traveling, either with a timestamp or snapshot ID.
Accessing by timestamp
Accessing with snapshot ID
Apache Hudi
Last but not least, there is Apache Hudi (pronounced ‘hoodie’). It is more stream-oriented than Iceberg or Delta Lake and more like an additional processing layer than only table format to use in the data lake. The main feature of Hudi is to introduce incremental architecture.
Time Travel Query is available only from v0.9.0 in the newest version of Hudi.
You can find more information about Apache Hudi architecture here:
https://cwiki.apache.org/confluence/display/HUDI/Design+And+Architecture
Time Travel Query is one of the newest features in Hudi. Before, such an action was possible with a combination of different queries. It supports the time travel nice syntax since the 0.9.0 version. Currently, three-time formats are supported as given below.
Modern technologies for data lakes take effort to provide time-traveling accessible and easy to use. Beyond table formats, there are other solutions supporting this feature like lakefs or hopsfs leveraging the capabilities of the aforementioned technologies.
Time traveling is a valuable feature for everybody that works in pipelines. Data Scientists can access historical models with ease; data engineers can quickly bring channels to a historical state in case of bugs that corrupt the data. It makes the job easier and faster to do everywhere where data evolve and changes frequently.
Read more articles

From Elisabeth I to AI – how does technology affect the labour market

Origin Story: From Teaching Through DNA to Artificial Intelligence

ML on a large scale – how to become MLOps

Billennium Healthcare Solutions

Risk in ML Projects. Is MLOps the Solution?

Become a Big Data & AI specialist. Proprietary training programs at Billennium

- Leadership & Development

MLOps is the key to success in ML projects

How Does MLOps Support Building of ML Models?
- Cloud Computing

Monitoring ML models using MLOps
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement . We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
[QUESTION] Athena Hudi Time Travel Queries #4502
leohoare commented Jan 3, 2022 • edited by xushiyan
- 👍 3 reactions
fedsp commented Jan 15, 2022
Sorry, something went wrong.
nsivabalan commented Jan 20, 2022
Nsivabalan commented jan 20, 2022 • edited.
fedsp commented Jan 20, 2022
xushiyan commented Jan 20, 2022
Nsivabalan commented jan 21, 2022, xushiyan commented feb 28, 2022.
maddy2u commented Dec 28, 2022
- 👀 1 reaction
IvyIvy1109 commented Jan 2, 2023
Maddy2u commented jan 2, 2023 via email.
No branches or pull requests
PrestoDB and Apache Hudi
Bhavani sudha saktheeswaran, software engineer at onehouse.
Apache Hudi is a fast growing data lake storage system that helps organizations build and manage petabyte-scale data lakes. Hudi brings stream style processing to batch-like big data by introducing primitives such as upserts, deletes and incremental queries. These features help surface faster, fresher data on a unified serving layer. Hudi tables can be stored on the Hadoop Distributed File System (HDFS) or cloud stores and integrates well with popular query engines such as Presto , Apache Hive , Apache Spark and Apache Impala . Given Hudi pioneered a new model that moved beyond just writing files to a more managed storage layer that interops with all major query engines, there were interesting learnings on how integration points evolved.
In this blog we are going to discuss how the Presto-Hudi integration has evolved over time and also discuss upcoming file listing and query planning improvements to Presto-Hudi queries.
Apache Hudi overview
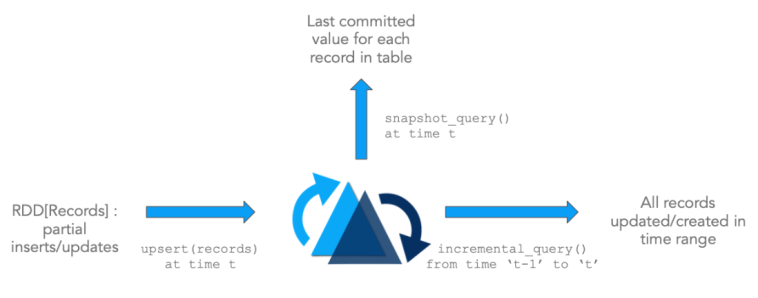
Apache Hudi (Hudi for short, here on) enables storing vast amounts of data on top of existing DFS compatible storage while also enabling stream processing in addition to typical batch-processing. This is made possible by providing two new primitives. Specifically,
- Update/Delete Records : Hudi provides support for updating/deleting records, using fine grained file/record level indexes, while providing transactional guarantees for the write operation. Queries process the last such committed snapshot, to produce results.
- Change Streams : Hudi also provides first-class support for obtaining an incremental stream of all the records that were updated/inserted/deleted in a given table, from a given point-in-time, and unlocks a new incremental-query category.

These primitives work closely hand-in-glove and unlock stream/incremental processing capabilities directly on top of DFS-abstractions. This is very similar to consuming events from a kafka-topic and then using a state-store to accumulate intermediate results incrementally. It has several architectural advantages.
- Increased Efficiency : Ingesting data often needs to deal with updates (resulting from database-change-capture), deletions (due to data-privacy-regulations) and enforcing unique-key-constraints (to ensure data-quality of event streams/analytics). However, due to lack of standardized support for such functionality, data engineers often resort to big batch jobs that reprocess entire day’s events or reload the entire upstream database every run, leading to massive waste of computational-resources. Since Hudi supports record level updates, it brings an order of magnitude improvement to these operations, by only reprocessing changed records and rewriting only the part of the table that was updated/deleted, as opposed to rewriting entire table-partitions or even the entire table.
- Faster ETL/Derived Pipelines : A ubiquitous next step, once the data has been ingested from external sources is to build derived data pipelines using Apache Spark/Apache Hive, or any other data processing framework, to ETL the ingested data for a variety of use-cases like data-warehousing, machine-learning-feature-extraction, or even just analytics. Typically, such processes again rely on batch-processing jobs, expressed in code or SQL, that process all input data in bulk and recompute all the output results. Such data pipelines can be sped up dramatically, by querying one or more input tables using an incremental-query instead of a regular snapshot-query, resulting in only processing the incremental changes from upstream tables, and then upsert or delete on the target derived table, as depicted in the first diagram.
- Access to fresh data : It’s not everyday we will find that reduced resource usage also results in improved performance, since typically we add more resources (e.g memory) to improve performance metric (e.g query latency). By fundamentally shifting away from how datasets have been traditionally managed, for what may be the first time since the dawn of the big data era, Hudi realizes this rare combination. A sweet side-effect of incrementalizing batch-processing is that the pipelines also take a much smaller amount of time to run. This puts data into hands of organizations much more quickly than has been possible with data-lakes before.
- Unified Storage : Building upon all the three benefits above, faster and lighter processing right on top of existing data-lakes mean lesser need for specialized storage or data-marts, simply for purposes of gaining access to near real-time data.
Types of Hudi tables and queries
Table types.
Hudi supports the following table types.
Copy On Write (COW) : Stores data using exclusively columnar file formats (e.g parquet). Updates version & rewrites the files by performing a synchronous merge during write.
Merge On Read (MOR) : Stores data using file versions with combination of columnar (e.g parquet) + row based (e.g avro) file formats. Updates are logged to delta files & later compacted to produce new versions of columnar files synchronously or asynchronously.
The following table summarizes the trade-offs between these two table types.
Query types
Hudi supports the following query types.
Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action. In case of merge-on-read table, it exposes near-real time data (few mins) by merging the base and delta files of the latest file version on-the-fly. For copy-on-write tables, it provides a drop-in replacement for existing parquet tables, while providing upsert/delete and other write side features.
Incremental Queries : Queries only see new data written to the table since a given commit/compaction. This effectively provides change streams to enable incremental data pipelines.
Read Optimized Queries : Queries see the latest snapshot of a table as of a given commit/compaction action. Exposes only the base/columnar files in latest file versions and guarantees the same columnar query performance compared to a non-hudi columnar table.
The following table summarizes the trade-offs between the different query types.
The following animations illustrate a simplified version of how inserts/updates are stored in a COW and a MOR table along with query results along the timeline. Note that X axis indicates the timeline and query results for each query type.
Note that the table’s commits are fully merged into the table as part of the write operation. For updates, the file containing the record is re-written with new values for all records that are changed. For inserts, the records are first packed onto the smallest file in each partition path, until it reaches the configured maximum size. Any remaining records after that, are again packed into new file id groups, again meeting the size requirements.
At a high level, MOR writer goes through the same stages as COW writer in ingesting data. The updates are appended to the latest log (delta) file belonging to the latest file version without merging. For inserts, Hudi supports 2 modes:
- Inserts to log files – This is done for tables that have an indexable log files (for e.g. hbase index or the upcoming record level index)
- Inserts to parquet files – This is done for tables that do not have indexable log files, for example bloom index
At a later time, the log files are merged with the base parquet file by compaction action in the timeline. This table type is the most versatile, highly advanced and offers much flexibility for writing (ability to specify different compaction policies, absorb bursty write traffic etc) and querying (e.g: tradeoff data freshness and query performance). At the same time, it can involve a learning curve for mastering it operationally.
Early Presto integration
Hudi was designed in mid to late 2016. At that time, we were looking to integrate with query engines in the Hadoop ecosystem. To achieve this in Presto, we introduced a custom annotation – @UseFileSplitsFromInputFormat , as suggested by the community. Any Hive registered table if it has this annotation would fetch splits by invoking the corresponding inputformat’s getSplits() method instead of Presto Hive’s native split loading logic. For Hudi tables queried via Presto this would be a simple call to HoodieParquetInputFormat.getSplits() . This was a straightforward and simple integration. All one had to do was drop in the corresponding Hudi jars under <presto_install>/plugin/hive-hadoop2/ directory. This supported querying COW Hudi tables and read optimized querying of MOR Hudi tables (only fetch data from compacted base parquet files). At Uber, this simple integration already supported over 100,000 Presto queries per day from 100s of petabytes of data (raw data and modeled tables) sitting in HDFS ingested using Hudi.
Moving away from InputFormat.getSplits()
While invoking inputformat.getSplits() was a simple integration, we noticed that this could cause a lot of RPC calls to namenode. There were several disadvantages to the previous approach.
- The InputSplit s returned from Hudi are not enough. Presto needs to know the file status and block locations for each of the InputSplit returned. So this added 2 extra RPCs to the namenode for every split times the number of partitions loaded. Occasionally, backpressure can be observed if the namenode is under a lot of pressure.
- Furthermore, for every partition loaded (per loadPartition() call) in Presto split calculation, HoodieParquetInputFormat.getSplits() would be invoked. That caused redundant Hoodie table metadata listing, which otherwise can be reused for all partitions belonging to a table scanned from a query.
This led us to rethink the Presto-Hudi integration. At Uber, we changed this implementation by adding a compile time dependency on Hudi and instantiated the HoodieTableMetadata once in the BackgroundHiveSplitLoader constructor. We then leveraged Hudi Library APIs to filter the partition files instead of calling HoodieParquetInputFormat.getSplits() . This gave a significant reduction in the number of namenode calls in this path.
Towards generalizing this approach and making it available for the Presto-Hudi community, we added a new API in Presto’s DirectoryLister interface that would take in a PathFilter object. For Hudi tables, we supplied this PathFilter object – HoodieROTablePathFilter , which would take care of filtering the files that Presto lists for querying Hudi tables and achieve the same results as Uber’s internal solution.
This change is available since the 0.233 version of Presto and depends on the 0.5.1-incubating Hudi version. Since Hudi is now a compile time dependency it is no longer necessary to provide Hudi jar files in the plugin directory.
Presto support for querying MOR tables in Hudi
We are starting to see more interest among the community to add support for snapshot querying of Hudi MOR tables from Presto. So far, from Presto, only read optimized queries (pure columnar data) are supported on Hudi tables. With this PR in progress – https://github.com/prestodb/presto/pull/14795 we are excited that snapshot querying (aka real time querying) of Hudi MOR tables will be available soon. This would make fresher data available for querying by merging base file (Parquet data) and log files (Avro data) at read time.
In Hive, this can be made available by introducing a separate InputFormat class that provides ways to deal with splits and a new RecordReader class that can scan the split to fetch records. For Hive to query MOR Hudi tables there is already such classes available in Hudi:
- InputFormat – org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
- InputSplit – org.apache.hudi.hadoop.realtime.HoodieRealtimeFileSplit
- RecordReader – org.apache.hudi.hadoop.realtime.HoodieRealtimeRecordReader Supporting this in Presto involves understanding how Presto fetches records from Hive tables and making necessary changes in that layer. Because Presto uses its native ParquetPageSource rather than the record reader from the input format, Presto would only show the base parquet files, and not show the real time upserts from Hudi’s log files which are avro data (essentially the same as a normal read-optimized Hudi query).
To allow Hudi real time queries to work, we identified and made the following separate necessary changes:
- Add extra metadata field to serializable HiveSplit to store Hudi split information. Presto-hive converts its splits into the serializable HiveSplit to pass around. Because it expects standard splits, it will lose the context of any extra information contained in complex splits extended from FileSplit . Our first thought was to simply add the entire complex split as an extra field of HiveSplit . This didn’t work however as the complex splits were not serializable and this would also duplicate the base split data. Instead we added a CustomSplitConverter interface. This accepts a custom split and returns an easily serializable String->String map containing the extra data from the custom split. To complement this, we also added this Map as an additional field to Presto’s HiveSplit . We created the HudiRealtimeSplitConverter to implement CustomSplitConverter interface for Hudi real time queries.
- Recreate Hudi split from HiveSplit ‘s extra metadata. Now that we have the full information of the custom split contained in HiveSplit , we need to identify and recreate the HoodieRealtimeFileSplit just before reading the split. The same CustomSplitConverter interface has another method that takes a normal FileSplit + extra split information map and returns the actual complex FileSplit, in this case the HudiRealtimeFileSplit . This leads to our last and final change.
- Use HoodieRealtimeRecordReader from HoodieParquetRealtimeInputFormat to read recreated HoodieRealtimeFileSplit . Presto needs to use the new record reader to properly handle the extra information in the HudiRealtimeFileSplit . To do this we introduced another annotation @UseRecordReaderFromInputFormat similar to the first annotation. This signals Presto to use the Hive record cursor (which uses the record reader from the input format) instead of the page source. The Hive record cursor sees the recreated custom split and sets additional information/configs based on the custom split.
With these changes, Presto users should be able to access more real time data on Hudi MOR tables.
What’s next?
Following are some interesting efforts (we call them RFCs ) we are looking into that may need support in Presto.
RFC-12: Bootstrapping Hudi tables efficiently
Apache Hudi maintains per record metadata that enables us to provide record level upserts, unique key semantics and database-like change streams. However, this meant that, to take advantage of Hudi’s upsert and incremental processing support, users would need to rewrite their whole dataset to make it an Apache Hudi table. This RFC provides a mechanism to efficiently migrate their datasets without the need to rewrite the entire dataset, while also providing the full capabilities of Hudi.
This will be achieved by having mechanisms to refer to the external data files (from the source table) from within the new bootstrapped Hudi table. With the possibility of data residing in an external location (bootstrapped data) or under Hudi table’s basepath (recent data), FileSplit s would require to store more metadata on these. This work would also leverage and build upon the Presto MOR query support we are adding currently.
Support Incremental and point in time time-travel queries on Hudi tables
Incremental queries allow us to extract change logs from a source Hudi table. Point in time queries allows for getting the state of a Hudi table between time T1 and T2. These are supported in Hive and Spark already. We are looking into supporting this feature in Presto as well.
In Hive incremental queries are supported by setting few configs in JobConf like for example – query mode to INCREMENTAL , starting commit time and max number of commits to consume. In Spark, there is a specific implementation to support incremental querying – IncrementalRelation . To support this in Presto, we need a way to identify the incremental query. Given Presto does not pass arbitrary session configs to the hadoop configuration object, an initial idea is to register the same table in the metastore as an incremental table. And then use query predicates to get other details such as starting commit time, max commits etc.
RFC-15: Query planning and listing improvements
Hudi write client and Hudi queries need to perform listStatus operation on the file system to get a current view of the file system. While at Uber, the HDFS infrastructure was heavily optimized for listing, this can be an expensive op for large datasets containing thousands of partitions and each partition having thousands of files on cloud/object storage. The above RFC work aims at eliminating list operation and providing better query performance and faster lookups, by simply incrementally compacting Hudi’s timeline metadata into a snapshot of a table’s state at that instant.
The solutions here aim at
- Ways for storing and maintaining metadata of the latest list of files.
- Maintaining stats on all columns of a table to aid effective pruning of files before scanning. This can be leveraged in the query planning phase of the engine.
Towards this, Presto would need some changes too. We are actively exploring ways to leverage such metadata in the query planning phase. This would be a significant addition to Presto-Hudi integration and would push the query latencies further down.
Record Level Indexes
Upsert is a popular write operation on Hudi tables that relies on indexing to tag incoming records as upserts. HoodieIndex provides a mapping of a record id to a file id in both a partitioned or a non-partitioned dataset, with implementations backed by BloomFilters/ Key ranges (for temporal data), and also Apache HBase (for random updates). Many users find Apache HBase (or any such key-value store backed index) expensive and adding to operational overhead. This effort tries to come up with a new index format for indexing at record level, natively within Hudi. Hudi would store and maintain the record level index (backed by pluggable storage implementations such as HFile, RocksDB). This would be used by both the writer (ingestion) and readers (ingestion/queries) and would significantly improve upsert performance over join based approaches or even bloom index for random update workloads. This is another area where query engines could leverage this information when pruning files before listing them. We are also looking at a way to leverage this metadata from Presto when querying.
Moving forward
Query engines like Presto are the gateways for users to reap the strength of Hudi. With an ever growing community and active development roadmap there are many interesting projects in Hudi. As Hudi invests heavily into the projects above, there is only greater need to deeply integrate with systems like Presto. Towards that, we look forward to collaborating with the Presto community. We welcome suggestions, feedback and encourage you to make contributions and connect with us here .
Public signup for this instance is disabled . Go to our Self serve sign up page to request an account.
- Apache Hudi
Time Travel (querying the historical versions of data) ability for Hudi Table
- Status: Open
- Resolution: Unresolved
- Affects Version/s: None
- Fix Version/s: None
- Component/s: Common Core
- Labels: None
Description
Hi, all: We plan to use Hudi to sync mysql binlog data. There will be a flink ETL task to consume binlog records from kafka and save data to hudi every one hour. The binlog records are also grouped every one hour and all records of one hour will be saved in one commit. The data transmission pipeline should be like – binlog -> kafka -> flink -> parquet.
After the data is synced to hudi, we want to querying the historical hourly versions of the Hudi table in hive SQL.
Here is a more detailed description of our issue along with a simply design of Time Travel for Hudi, the design is under development and testing:
https://docs.google.com/document/d/1r0iwUsklw9aKSDMzZaiq43dy57cSJSAqT9KCvgjbtUo/edit?usp=sharing
We have to support Time Travel ability recently for our business needs. We also have seen the RFC 07 . Be glad to receive any suggestion or dicussion.
Attachments
Apache Hudi and Lake Formation
Amazon EMR releases 6.15.0 and higher include support for fine-grained access control based on AWS Lake Formation with Apache Hudi when you read and write data with Spark SQL. Amazon EMR supports table, row, column, and cell-level access control with Apache Hudi. With this feature, you can run snapshot queries on copy-on-write tables to query the latest snapshot of the table at a given commit or compaction instant.
Currently, a Lake Formation-enabled Amazon EMR cluster must retrieve Hudi's commit time column to perform incremental queries and time travel queries. It doesn't support Spark's timestamp as of syntax and the Spark.read() function. The correct syntax is select * from table where _hoodie_commit_time <= point_in_time . For more information, see Point in time Time-Travel queries on Hudi table .
The following support matrix lists some core features of Apache Hudi with Lake Formation:
Querying Hudi tables
This section shows how you can run the supported queries described above on a Lake Formation enabled cluster. The table should be a registered catalog table.
To start the Spark shell, use the following commands.
If you want Lake Formation to use record server to manage your Spark catalog, set spark.sql.catalog.<managed_catalog_name>.lf.managed to true.
To query the latest snapshot of copy-on-write tables, use the following commands.
To query the latest compacted data of MOR tables, you can query the read-optimized table that is suffixed with _ro :
The performance of reads on Lake Formation clusters might be slower because of optimizations that are not supported. These features include file listing based on Hudi metadata, and data skipping. We recommend that you test your application performance to ensure that it meets your requirements.

To use the Amazon Web Services Documentation, Javascript must be enabled. Please refer to your browser's Help pages for instructions.
Thanks for letting us know we're doing a good job!
If you've got a moment, please tell us what we did right so we can do more of it.
Thanks for letting us know this page needs work. We're sorry we let you down.
If you've got a moment, please tell us how we can make the documentation better.
Dear Abby: Why should I spend time, money on travel to see relatives when they never come to visit me?
- Published: May. 02, 2024, 10:07 a.m.

This one-sided family relationship is costing this member a lot in travel expenses. Getty Images.
- Abigail Van Buren
DEAR ABBY: I have been independent from my family for 25 years. I have always lived a few hours’ drive from them. (I now live an hour away from my mother and three hours from my sister and her family.)
For every occasion over those 25 years, I have always visited them -- spending time, money on gas, putting thousands of miles on my car and sometimes taking time off from work. Never has anyone visited me, other than once when my sister was passing through and wanted to have lunch.
I have invited my family countless times, but there’s always an excuse. Often, it’s that my place is too small to accommodate them or that I have a roommate. I’m expected to spend my resources visiting them or go broke to have a place that can accommodate them. I am reminded of this lopsided situation every time my roommate’s family visits multiple times per year. They stay in hotels.
I’m not confrontational. I love my family, but I feel some boundaries need to be established. Am I unreasonable? If not, do you have any suggestions? -- ALL ON ME IN FLORIDA
DEAR ALL: If it is not practical to continue traveling to visit your relatives, stop doing it. Do not stop inviting them to visit you, however, and when you do, tell them you know they would be more comfortable staying in a nearby hotel or motel, which is what your roommate’s family has been doing for years.

Stories by Abigail Van Buren
- Dear Abby: Divorced woman’s son has oversized influence on her life choices
- Dear Abby: How do I get out of marriage to a cheating, reckless, abusive wife?
- Dear Abby: Husband accidentally discovers his wife has been cheating on him for 10 years
- Dear Abby: I made huge mistake taking in my son, his girlfriend and 2 kids. Now what?
- Dear Abby: How do I deal with heartbreak of falling for my boss when she’s not interested?
Dear Abby is written by Abigail Van Buren, also known as Jeanne Phillips, and was founded by her mother, Pauline Phillips. Contact Dear Abby at www.DearAbby.com or P.O. Box 69440, Los Angeles, CA 90069.
If you purchase a product or register for an account through a link on our site, we may receive compensation. By using this site, you consent to our User Agreement and agree that your clicks, interactions, and personal information may be collected, recorded, and/or stored by us and social media and other third-party partners in accordance with our Privacy Policy.
President Biden consoles families of law-enforcement officers gunned down in Charlotte

CHARLOTTE – President Joe Biden reprised his familiar role as consoler-in-chief on Thursday as he met privately with the families of four police officers killed in a shooting earlier this week in North Carolina.
Biden was already scheduled to travel to Wilmington, North Carolina, to deliver a speech on rebuilding infrastructure and creating good-paying jobs. The White House added a stop to Charlotte to his itinerary.
Biden met with family members at the North Carolina Air National Guard base, situated at the Charlotte Douglas International Airport, where Biden stopped for more than two hours during his North Carolina swing. It was not immediately clear how long Biden met with the families.
The four officers were killed Monday when a gunman with a high-powered rifle opened fire on them from the second floor of a residence while a task force made up of officers from several agencies was attempting to serve a felony warrant in Charlotte. Multiple officers were hit, and the other task force members called in reinforcements.
As local police arrived and began to rescue the downed task force members, more gunfire came from the house and additional officers were struck, police said.
Prep for the polls: See who is running for president and compare where they stand on key issues in our Voter Guide
Killed were Sam Poloche, 42, and Alden Elliot, 46, both with the state's Department of Adult Correction; Deputy U.S. Marshal Thomas M. Weeks Jr., 48, of Mooresville, North Carolina; and Charlotte-Mecklenburg Police Department Officer Joshua Eyer, 31.
Four other officers were wounded in the attack.
More: Investigators continue piecing together Charlotte shooting that killed 4 officers
The gunman, identified as 39-year-old Terry Clark Hughes Jr., exited the house with a firearm and was shot by police. He was pronounced dead on the front lawn.
In a statement on Monday, Biden described the fallen officers as “heroes who made the ultimate sacrifice, rushing into harm’s way to protect us.” The death of a police officer is “like losing a piece of your soul,” he said.
Biden's meeting with the families of the slain officers in Charlotte also included officers wounded in the shooting, along with other law enforcement officers and elected officials.
Biden has been forced to take on the role of consoler-in-chief multiple times during his presidency, comforting the families of hurricanes, tornados and other natural disasters, along with the victims of mass shootings in cities ranging from Buffalo to Las Vegas and Uvalde, Texas to Lewiston, Maine .
Contributing: Joey Garrison. Michael Collins covers the White House. Follow him on X, formerly Twitter, @mcollinsNEWS.
Time travel and surveillance state paranoia collide in a witty, thought-provoking romance novel

- Show more sharing options
- Copy Link URL Copied!
Book Review
The Ministry of Time
By Kaliane Bradley Avid Reader Press: 352 pages, $28.99 If you buy books linked on our site, The Times may earn a commission from Bookshop.org , whose fees support independent bookstores.
“People aren’t history,” scoffs Adela, vice secretary of the Ministry, whose work is shrouded in secrecy and subterfuge. This retort comes late in Kaliane Bradley’s debut novel, “The Ministry of Time,” but it’s a telling line. Its dismissal of individual lives reveals the novel’s stakes. If people aren’t history, what is? This is a disturbing statement to come out of the mouth of a high-ranking British bureaucrat. For a book that could also be easily described as witty, sexy escapist fiction, “The Ministry of Time” packs a substantial punch.
Of late, many critically acclaimed books embrace mystery and absurdity in a way that both suspends and expands conventionally held notions of time. Hilary Leichter’s “Terrace Story,” National Book Critics Circle award winner Lorrie Moore’s “I Am Not Homeless If This Is Not My Home,” Ali Smith’s “Companion Piece,” National Book Award winner Justin Torres’ “Blackouts,” and Marie-Helene Bertino’s “Beautyland,” among others, forge poignant, bracing emotional connections. Their playfulness reveals possibilities and perspectives that might be lost in a novel bound by fact-checked 21st century reality. After all, in a world where nothing feels normal, fiction that embraces a disregard for physics and convention mirrors our new upside-down quotidian life.

To this end, Kaliane Bradley proves that it’s possible to address imperialism, the scourge of bureaucracy, cross-cultural conflict and the paranoia inherent in a surveillance state through her utterly entertaining novel. “The Ministry of Time” begins with a sixth-round job interview for an undisclosed position. The unnamed narrator is caught off guard when “the interviewer said my name, which made my thoughts clip. I don’t say my name, not even in my head. She’d said it correctly, which people generally don’t.” For the narrator, who “plateaued” as a “translator-consultant” in the Languages department of the Ministry of Defense, this top-secret job that pays three times her current salary is worth the mystery.
Soon the work is disclosed. The narrator, whose mother immigrated to the United Kingdom from Cambodia, will be working closely with people who might bristle at the term “refugees.” She’s now part of the Ministry of Expatriation working with one of five “expats” scavenged from the past. Confident in her storytelling, Bradley sweeps away the details of how and why time travel exists in the novel.

A disorienting, masterful, shape-shifting novel about multiracial identity
Rachel Khong’s irresistible puzzle of a second novel suggests it is a mistake to think we can force complex, nature-nurture identities in a chosen direction.
April 22, 2024
“All you need to know is that in your near future, the British government developed the means to travel through time but had not yet experimented with doing it.” With that, from the jump, readers and characters alike are asked to take a leap of faith as the narrator assumes the role of a “bridge” between an “expat” and modern life. The larger purpose of her work is elusive to her as well, but, in short, the narrator is tasked to be the roommate of an explorer named Commander Graham Gore who died on a doomed Royal Navy Arctic exhibition in 1847. He’s mannered, understandably jumpy, but also rather sexy for someone who died close to 200 years ago. Will this be an odd sort of meet-cute, or is something more chaotic afoot?
Buckle up, the ride has just begun. Juggling notions of “hereness” (the present) and “thereness” (the past), the novel’s five expats come to grips — or not — with the fact that they have been snatched from the past. The ministry selected individuals who were on the point of death so that their departures from the past would in no way rupture their historic timelines. But how would they affect the present? The bridges take notes, and medical examinations are de rigueur, but these collected data are merely passed along without much in the way of analysis.
The expats and bridges adjust to life together in a largely amusing fashion, sharing lovely homes provided by the ministry, visiting pubs, learning about the very existence of cinema. Music streaming services are a hit, but, generally speaking, the expats find it hard to accept the scale of modern life. Whether this is due to some physical mutation created by the process of time travel or if it’s merely the challenge of cultural displacement for people “loose as dust in narrative time,” true fissures begin to surface.

How many lives can one author live? In new short stories, Amor Towles invites us along for the ride
For fans who worry that a volume comprising six stories and a novella won’t serve up the deeper delights of his novels, prepare for what may be Towles’ best book yet.
March 29, 2024
In a manner that feels wholly unsurprising to the reader, suspicions arise as to the nature of the project. Why exactly is there a need for secrecy and what are the particulars about this ability to time travel that we’re asked to tacitly accept? Tensions also flare between the narrator and another bridge, Simellia, who are the two people of color in this tightly knit circle. The specter of imperialism looms and informs a certain tension between the narrator and Gore. Yet, as a green bureaucrat, happy to rise in the ranks, she confronts Simellia, saying, “You signed up for this job… [knowing], as much as I did, that what we were doing was world-changing. That’s what you wanted, remember? Do you think the world changes by being asked politely? Or do you think there has to be risk?”
But this brash confidence begins to waver. The narrator recognizes, “Every time I gave Graham a book, I was trying to shunt him along a story I’d been telling myself all my life.” Then she notes that the ministry “fed us all poison from a bottle marked ‘prestige’ and we developed a high tolerance for bitterness.” While the book does assume some obvious postures of university level post-colonial theory and language, it moves past these more cliched moments by focusing its attention on the characters. A tight narrative rich with witty banter, cutting observations and interspersed passages from Gore’s doomed expedition also keep the novel taut.
“Maybe I was tired of stories, telling them and hearing them,” muses the narrator. Curiously, while she made languages her profession (hence her tendency to consider that “the great project of Empire was to categorize: owned and owner, coloniser and colonised, evolué and barbarian, mine and yours.”), her antagonistic younger sister became a writer. Finding herself falling in love with Gore, the narrator becomes the story, upending history.
As the story’s momentum builds into that of a spy thriller, Bradley pulls off a rare feat. “The Ministry of Time” is a novel that doesn’t stoop to easy answers and doesn’t devolve into polemic. It’s a smart, gripping work that’s also a feast for the senses. An assassination, moles, questions of identity and violence wreak havoc on our happy lovers and the bubble they create in London. Yet our affection for them is as fresh and thrilling as theirs is for one another, two explorers of a kind, caught in a brilliant discovery. Bradley’s written an edgy, playful and provocative book that’s likely to be the most thought-provoking romance novel of the summer. Check your history: That’s no small feat.
Lauren LeBlanc is a board member of the National Book Critics Circle.
More to Read

Colm Tóibín’s latest tale is bound together by the tension between secrecy and revelation
May 3, 2024

Review: Long before Bond, ‘The Ministry of Ungentlemanly Warfare’ kicked off British covert ops
April 18, 2024

Review: Brilliantly acted, HBO’s ‘The Regime’ flirts with satire but lacks political bite
March 2, 2024
A cure for the common opinion
Get thought-provoking perspectives with our weekly newsletter.
You may occasionally receive promotional content from the Los Angeles Times.
More From the Los Angeles Times

10 books to add to your reading list in May
May 1, 2024

‘Disability Intimacy’ starts a long-overdue conversation
April 26, 2024

In Jane Smiley’s rock ’n’ roll novel, does good sense make good fiction?
April 19, 2024

A mysterious photographer of the Civil War, under a new microscope
Biden to travel to North Carolina to meet with families of officers killed in deadly shooting
President Joe Biden is expected to travel to North Carolina on Thursday to meet with the family members of four officers killed earlier this week in the deadliest attack on U.S. law enforcement since 2016
CHARLOTTE, N.C. — President Joe Biden is expected to travel to North Carolina on Thursday to meet with the family members of four officers killed earlier this week in the deadliest attack on U.S. law enforcement since 2016.
The president is scheduled to visit Wilmington across the state that day and is planning to add a stop in Charlotte to meet with local officials and the families of officers shot Monday while serving a warrant, according to a person familiar with the matter.
The four officers were killed when a task force made up of officers from different agencies arrived in the residential neighborhood in the city of 900,000 to try to capture 39-year-old Terry Clark Hughes Jr. on warrants for possession of a firearm by an ex-felon and fleeing to elude in Lincoln County, North Carolina. Hughes was also killed.
Four other officers were wounded in the shootout, and an AR-15 semi-automatic rifle, a 40-caliber handgun and ammunition were found at the scene. Those killed were identified as Sam Poloche and William Elliott of the North Carolina Department of Adult Corrections; Charlotte-Mecklenburg Officer Joshua Eyer; and Deputy U.S. Marshal Thomas Weeks.
After the attack, Biden expressed his condolences and support for the community, calling the slain officers “heroes who made the ultimate sacrifice, rushing into harm’s way to protect us.”
“We must do more to protect our law enforcement officers. That means funding them – so they have the resources they need to do their jobs and keep us safe. And it means taking additional action to combat the scourge of gun violence. Now,” Biden said in a statement, calling on leaders in Congress to pass a ban on assault weapons, among other gun control measures.
Outside the Charlotte Mecklenburg Police Department’s North Tryon Division on Wednesday, Eyer’s patrol car was draped with an American flag and covered with flower bouquets from community members who stopped to pay their respects.
The department called the vehicle a “solemn tribute” and “visible reminder of Officer Eyer’s sacrifice and service,” in a post on X, the platform formerly known as Twitter. Eyer’s memorial service is scheduled for Friday at a Charlotte Baptist church.
Also on Wednesday, a local police chief said that an officer from his force who was shot Monday underwent surgery and is expected to make a full recovery. David W. Onley, the police chief of Statesville in the Charlotte metropolitan area, expressed condolences Wednesday and “unwavering solidarity with our law enforcement brethren during this difficult time,” according to a statement released by his office.
One of the four officers injured in the attack was Cpl. Casey Hoover of the Statesville Police Department, who served on the task force. He was shot in his upper torso — an area unprotected by his bulletproof vest.
Hoover was taken by the Charlotte-Mecklenburg Police Department to a Charlotte hospital, where he underwent surgery. Onley said the officer, who has worked for the Statesville police for eight years, is now stable and is expected to make a full recovery and “exemplifies the bravery and resilience of our law enforcement community.”
Law enforcement officers were still investigating Wednesday, attempting to determine a precise timeline of events and whether Hughes acted alone or with a second shooter.
Hughes’ criminal record in North Carolina goes back more than a decade. It includes prison time and convictions for breaking and entering, reckless driving, eluding arrest and illegally possessing a gun as a former felon, according to state records.
The attack was the deadliest day for U.S. law enforcement in one incident since five officers were killed by a sniper during a protest in Dallas in 2016.
___ Miller reported from Washington.

Querying Data
This page is no longer maintained. Please refer to Hudi SQL DDL , SQL DML , SQL Queries and Procedures for the latest documentation.
Conceptually, Hudi stores data physically once on DFS, while providing 3 different ways of querying, as explained before . Once the table is synced to the Hive metastore, it provides external Hive tables backed by Hudi's custom inputformats. Once the proper hudi bundle has been installed, the table can be queried by popular query engines like Hive, Spark SQL, Flink, Trino and PrestoDB.
In sections, below we will discuss specific setup to access different query types from different query engines.
Spark Datasource
The Spark Datasource API is a popular way of authoring Spark ETL pipelines. Hudi tables can be queried via the Spark datasource with a simple spark.read.parquet . See the Spark Quick Start for more examples of Spark datasource reading queries.
If your Spark environment does not have the Hudi jars installed, add hudi-spark-bundle jar to the classpath of drivers and executors using --jars option. Alternatively, hudi-spark-bundle can also fetched via the --packages options (e.g: --packages org.apache.hudi:hudi-spark-bundle_2.11:0.13.0).
Snapshot query
Retrieve the data table at the present point in time.
Incremental query
Of special interest to spark pipelines, is Hudi's ability to support incremental queries, like below. A sample incremental query, that will obtain all records written since beginInstantTime , looks like below. Thanks to Hudi's support for record level change streams, these incremental pipelines often offer 10x efficiency over batch counterparts by only processing the changed records.
The following snippet shows how to obtain all records changed after beginInstantTime and run some SQL on them.
For examples, refer to Incremental Queries in the Spark quickstart. Please refer to configurations section, to view all datasource options.
Additionally, HoodieReadClient offers the following functionality using Hudi's implicit indexing.
HiveIncrementalPuller allows incrementally extracting changes from large fact/dimension tables via HiveQL, combining the benefits of Hive (reliably process complex SQL queries) and incremental primitives (speed up querying tables incrementally instead of scanning fully). The tool uses Hive JDBC to run the hive query and saves its results in a temp table. that can later be upserted. Upsert utility ( HoodieStreamer ) has all the state it needs from the directory structure to know what should be the commit time on the target table. e.g: /app/incremental-hql/intermediate/{source_table_name}_temp/{last_commit_included} .The Delta Hive table registered will be of the form {tmpdb}.{source_table}_{last_commit_included} .
The following are the configuration options for HiveIncrementalPuller
Setting fromCommitTime=0 and maxCommits=-1 will fetch the entire source table and can be used to initiate backfills. If the target table is a Hudi table, then the utility can determine if the target table has no commits or is behind more than 24 hour (this is configurable), it will automatically use the backfill configuration, since applying the last 24 hours incrementally could take more time than doing a backfill. The current limitation of the tool is the lack of support for self-joining the same table in mixed mode (snapshot and incremental modes).
- Snapshot query
- Incremental query
IMAGES
VIDEO
COMMENTS
Change Data Capture (CDC) queries are useful when you want to obtain all changes to a Hudi table within a given time window, along with before/after images and change operation of the changed records. ... Time Travel: consume as batch for an instant time, specify the read.end-commit is enough because the start commit is latest by default.
There are 2 options here : 1) Hudi provides a list of timestamps that can be supplied by the user as the point_in_time the user wants to query against. Hudi writes the commit/ def~instant-time s to a timeline metadata folder and provides API's to read the timeline.
query_data(): This function queries the Hudi table and displays the results. time_travel_query(): This function demonstrates time travel querying capability by reading data at different points in ...
Time Travel Query is one of the newest features in Hudi. Before, such an action was possible with a combination of different queries. It supports the time travel nice syntax since the 0.9.0 version. Currently, three-time formats are supported as given below.
Hudi was built as the manifestation of this vision, ... is the need for expiring snapshots/controlling retention for time travel queries such that it does not interfere with query planning ...
On the other hand, Time Travel Queries take advantage of Hudi's ability to maintain historical data versions. This feature allows users to access and query data as it existed at any given point ...
Just a quick question that might even end up as yes/no. I've been looking into having a Hudi table queried by Athena. And wondering about the compatibility of time travel queries. To my understanding, there is functionality with presto/spark but this isn't supported in hive. in order to build the time travel query use _hoodie_commit_time.
As the data lake is expanded to additional use cases, there are still some use cases that are very difficult with data lakes, such as CDC (change data capture), time travel (querying point-in-time data), privacy regulation requiring deletion of data, concurrent writes, and consistency regarding handling small file problems.
Support Incremental and point in time time-travel queries on Hudi tables. Incremental queries allow us to extract change logs from a source Hudi table. Point in time queries allows for getting the state of a Hudi table between time T1 and T2. These are supported in Hive and Spark already. We are looking into supporting this feature in Presto as ...
I know Hudi (also Delta Lake and Iceberg) have this time-travel capability, and I'm wondering if I can use it to construct a machine learning training dataframe. Essentially, I'd love to tell Hudi, for each row in a dataframe, here's the timestamp column, join the feature data in Hudi that's correct as of the time value in the timestamp column.
Insert | Update | Read | Write | SnapShot | Time Travel | Clustering |incremental Query on Apache Hudi transaction data lake S3Code :https://github.com/soumi...
Another challenge is making concurrent changes to the data lake. Implementing these tasks is time consuming and costly. In this post, we explore three open-source transactional file formats: Apache Hudi, Apache Iceberg, and Delta Lake to help us to overcome these data lake challenges.
With a MoR dataset, each time there is an update, Hudi writes only the row for the changed record. MoR is better suited for write- or change-heavy workloads with fewer reads. CoW is better suited for read-heavy workloads on data that change less frequently. Hudi provides three query types for accessing the data: ...
With Hudi, time travel becomes a reality, allowing you to explore and analyze data from different points in time with remarkable ease. Debugging Made Easy: Data evolution can be complex, but ...
The data transmission pipeline should be like - binlog -> kafka -> flink -> parquet. After the data is synced to hudi, we want to querying the historical hourly versions of the Hudi table in hive SQL. Here is a more detailed description of our issue along with a simply design of Time Travel for Hudi, the design is under development and ...
Currently, a Lake Formation-enabled Amazon EMR cluster must retrieve Hudi's commit time column to perform incremental queries and time travel queries. It doesn't support Spark's timestamp as of syntax and the Spark.read() function. The correct syntax is select * from table where _hoodie_commit_time <= point_in_time.
Mid-to-late August is the best time for Americans to fly this summer, according to travel company Expedia. It's expected to be a less busy time, and Expedia says travelers can save up to $265 on ...
Court also let out early on April 22 and April 23 to allow people to travel for religious gatherings. ... Proceedings typically start at 9:30 a.m. local time and run through the business day ...
The Red Line is next to go through closures as part of the MBTA's Track Improvement Plan, and the transit agency is telling riders to plan for extra travel time for several weeks in May ...
The more the no of historic commits, the more back in time we can travel in case of incremental consumption, rollback and point-in-time query. Query types Hudi supports the following query types ...
DEAR ABBY: I have been independent from my family for 25 years. I have always lived a few hours' drive from them. (I now live an hour away from my mother and three hours from my sister and her ...
Biden was already scheduled to travel to Wilmington, North Carolina, to deliver a speech on rebuilding infrastructure and creating good-paying jobs. The White House added a stop to Charlotte to ...
Book Review. The Ministry of Time. By Kaliane Bradley Avid Reader Press: 352 pages, $28.99 If you buy books linked on our site, The Times may earn a commission from Bookshop.org, whose fees ...
Timeline. At its core, Hudi maintains a timeline which is a log of all actions performed on the table at different instants of time that helps provide instantaneous views of the table, while also efficiently supporting retrieval of data in the order of arrival. A Hudi instant consists of the following components. Instant action: Type of action performed on the table
July 21, 2021. vinoth. 29 min read. datalake platform. blog. apache hudi. As early as 2016, we set out a bold, new vision reimagining batch data processing through a new " incremental " data processing stack - alongside the existing batch and streaming stacks. While a stream processing pipeline does row-oriented processing, delivering a few ...
CHARLOTTE, N.C. — President Joe Biden is expected to travel to North Carolina on Thursday to meet with the family members of four officers killed earlier this week in the deadliest attack on U.S ...
Conceptually, Hudi stores data physically once on DFS, while providing 3 different ways of querying, as explained before . Once the table is synced to the Hive metastore, it provides external Hive tables backed by Hudi's custom inputformats. Once the proper hudi bundle has been installed, the table can be queried by popular query engines like ...